다중공선성문제는 통계학의 회귀분석에서 독립변수들 간에 강한 상관관계가 나타나는 문제이다. 독립변수들간에 정확한 선형관계가 존재하는 완전공선성의 경우와 독립변수들간에 높은 선형관계가 존재하는 다중공선성으로 구분하기도 한다.
이진 분류에 자주 사용되는 모델인 로지스틱 회귀모형을 다루게 되면 필히 다뤄야할 내용이다.
이번 블로깅은 다중공선성 문제를 해결해 나가는 방법에 대해 다뤄보겠다.
# WDBC 데이터셋의 diagnosis 진단 변수는 목표변수(반응변수, 종속변수, Output 변수)로서
# 2개의 class (악성 Malignant, 양성 Benign)를 가진 범주형 자료로서, 30개의 연속형 설명변수를
# 사용해서 2개의 class (악성, 양성 여부)를 분류(classification) 하는 해야합니다.
# 30개의 설명변수를 사용하여 유방암 악성(Malignant)에 속할 0~1 사이의 확률값을 계산하여 진단하는 분류/예측 모델을 만들어보겠습니다.
# https://www.kaggle.com/uciml/breast-cancer-wisconsin-data 데이터 주소
data <- read.csv("C:/Users/inp032/Desktop/회사자료/Ai 프로젝트/data.csv")
data
head(data)
data.frame(data)
str(data)
summary(data)
#M,B 종속변수 값을 1,0 으로 바꿔줌
Y <- ifelse(data$diagnosis == 'M', 1, 0)
X <- data[,c(3:32)]

데이터는 30개의 컬럼으로 이루어져 있고 총 569개의 데이터가 존재한다.
VIF(lm(radius_mean ~ .,data=data))
VIF(lm(texture_mean ~ .,data=data))
require(fmsb)
vif_func <- function(in_frame,thresh=10, trace=F,...){
require(fmsb)
if(class(in_frame) != 'data.frame') in_frame<-data.frame(in_frame)
vif_init <- vector('list', length = ncol(in_frame))
names(vif_init) <- names(in_frame)
var_names <- names(in_frame)
for(val in var_names){
regressors <- var_names[-which(var_names == val)]
form <- paste(regressors, collapse = '+')
form_in <- formula(paste(val,' ~ .'))
vif_init[[val]] <- VIF(lm(form_in,data=in_frame,...))
}
vif_max<-max(unlist(vif_init))
if(vif_max < thresh){
if(trace==T){ #print output of each iteration
prmatrix(vif_init,collab=c('var','vif'),rowlab=rep('', times = nrow(vif_init) ),quote=F)
cat('\n')
cat(paste('All variables have VIF < ', thresh,', max VIF ',round(vif_max,2), sep=''),'\n\n')
}
return(names(in_frame))
}
else{
in_dat<-in_frame
#backwards selection of explanatory variables, stops when all VIF values are below 'thresh'
while(vif_max >= thresh){
vif_vals <- vector('list', length = ncol(in_dat))
names(vif_vals) <- names(in_dat)
var_names <- names(in_dat)
for(val in var_names){
regressors <- var_names[-which(var_names == val)]
form <- paste(regressors, collapse = '+')
form_in <- formula(paste(val,' ~ .'))
vif_add <- VIF(lm(form_in,data=in_dat,...))
vif_vals[[val]] <- vif_add
}
max_row <- which.max(vif_vals)
#max_row <- which( as.vector(vif_vals) == max(as.vector(vif_vals)) )
vif_max<-vif_vals[max_row]
if(vif_max<thresh) break
if(trace==T){ #print output of each iteration
vif_vals <- do.call('rbind', vif_vals)
vif_vals
prmatrix(vif_vals,collab='vif',rowlab=row.names(vif_vals),quote=F)
cat('\n')
cat('removed: ', names(vif_max),unlist(vif_max),'\n\n')
flush.console()
}
in_dat<-in_dat[,!names(in_dat) %in% names(vif_max)]
}
return(names(in_dat))
}
}
for문을 이용하여 함수를 만들었다. 다중공선성은 보통 분산팽창지수인 vif값이 10이상인 경우 다중공선성이 심각하다고 판단 된다. 내가 for문을 이용한 이유는 제일 먼저 vif값이 높은 변수를 지우고 그 다음 다시 vif값을 계산해서 다시 제일 높은 vif값을 가지고 있는 변수를 제거하는 방법이다. 10이상인 값이 존재하지 않을때 for문은 멈추게 된다.
함수를 이제 대입시켜 준다.
#다중공선성이 높은 컬럼 지워주기
data_custom <- vif_func(X, thresh=10, trace=T)
#남은 데이터 갯수 확인하기
length(data_custom)
X_2 <- X[, data_custom]
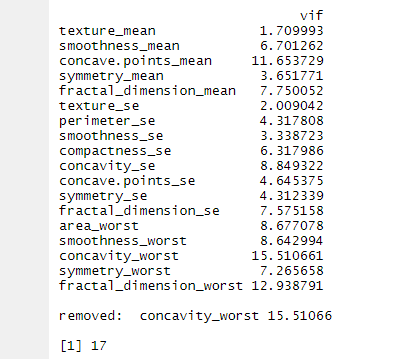
반복 되고 마지막엔 30개에서 13개가 지워져서 17개의 데이터만 남았다.