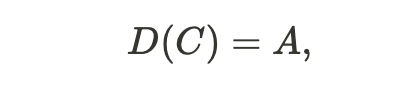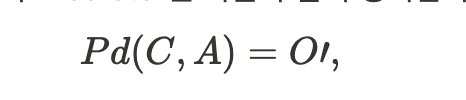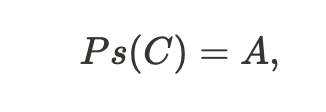Abstract
- 기존 sequence transduction model들은 인코더와 디코더를 포함한 복잡한 recurrent 나 cnn에 기반
- 가장 성능이 좋은 모델 또한 attention mechanism으로 인코더와 디코더를 연결한 구조
- Transformer는 온전히 attention mechanism에만 기반함
- recurrence 나 convolution은 사용하지 않음
- 더 parallelizable하고, 훨씬 적은 학습 시간이 걸림
Introduction
- Recurrent model은 parallelization이 불가능해 longer sequence length에서 치명적
- Attention mechanism 은 다양한 분야의 sequence modeling과 transduction model에서 주요하게 다뤄짐
- Transformer는 input과 output간 global dependency를 뽑아내기 위해 recurrence를 사용하지 않고, attention mechanism만을 사용함
Background
sequential computation을 줄이는 것은 Extended Neural GPU, ByteNet, ConvS2S에서도 다뤄짐
- 이 연구들은 모두 CNN을 basic building block으로 사용함
- input output 거리에서 dependency를 학습하기 어려움
- Transformer에서는 Multi-Head Attention 으로 상수 시간으로 줄어듦
Self-attenion(=intra-attention)
- reading comprehension, abstractive summarization, textual entailment, learning task, independent sentence representations를 포함한 다양한 task에서 성공적으로 사용됨
End-to-end memory network
- sequence-aligned recurrence 보다 recurrent attention mechanism에 기반함
- simple-language question answering 과 language modeling task에서 좋은 성능을 보임
Model Architecture
(1) Encoder and Decoder Stacks

Encoder
- Encoder는 6개의 identical layer로 이루어짐
- 각 layer는 두 개의 sub-layer가 있음
- 첫 번째 sub-layer는 multi-head self-attention mechanism
- 두 번째 sub-layer는 간단한 position-wise fully connected feed-forward network
- 각 two sub-layers 마다 layer normalization 후에 residual connection을 사용함
- 즉 각 sub-layer의 결과는 LayerNorm(x+Sublayer(x)) 임
- residual connection을 구현하기 위해, embedding layer를 포함한 모든 sub-layer들의 output은 512 차원임
- dmodel = 512
Decoder
- Decoder도 마찬가지로 6개의 identical layer로 이루어짐
- 각 Encoder layer의 두 sub-layer에, decoder는 세번째 sub-layer를 추가함
- encoder stack의 결과에 해당 layer가 multi-head attention을 수행함
- 마찬가지로 residual connection 적용
(2) Attention
- Scaled Dot-Product Attention

- Query q는 어떤 단어를 나타내는 vector이고, K는 문장의 모든 단어들에 대한 vector들을 stack해놓은 matrix
- Attention function은 쿼리와 key-value쌍을 output에 매핑함 (query,key,value,output은 모두 vector임) output은 value들의 weighted sum으로 계산됨
- 하나의 단어, 모든 단어들의 dot product를 함으로써 어떠한 Relation vector를 만듦
- 두 가지 Attention function
-
- Additive attention : single hidden layer로 feed-forward layer network를 사용해 compatibility function을 계산
- Dot-product attention : scaling factor (1√dk) 를 제외하면 이 연구에서의 attention 방식과 동일
- dot-product 방식이 더 빠르고 공간 효율적임
- 기존 방식과 다르게 1/√dk로 스케일링함. 논문에서는 이를 softmax가 0 근처에서는 gradient가 높고, large positive and large negative value들에 대해서는 매우 낮은 gradient를 가지기 때문에 학습이 잘 되지 않는 문제가 일어나고, scaling을 통해 모든 값들이 0 근처에 오도록 만들어줌으로써 이러한 문제를 해결한다고함
2. Multi-Head Attention

- Single attention을 dmodel-dimensional keys, values, queries에 적용하는 것보다, queries, keys, values를 h번 서로 다른, 학습된 linear projection으로 dk, dk와dv차원에 linear하게 project하는 게 더 효과적이라는 사실을 알아냄

3. Transformer는 세 가지 방법으로 multi-head attention을 사용함
- 인코더-디코더 attention layers
- query는 이전 디코더 layer에서 나옴
- memory key와 value는 인코더의 output에서 나옴
- 따라서 디코더의 모든 position이 input sequence의 모든 position을 다룸
- 전형적인 sequence-to-sequence model에서의 인코더-디코더 attention 방식임
- 인코더는 self-attention layer를 포함
- self-attention layer에서 key, value, query는 모두 같은 곳(인코더의 이전 layer의 output)에서 나옴
- 인코더의 각 position은 인코더의 이전 layer의 모든 position을 다룰 수 있음
- 디코더 또한 self-attention layer를 가짐
- 마찬가지로, 디코더의 각 position은 해당 position까지 모든 position을 다룰 수 있음
- 디코더의 leftforward information flow는 auto-regressive property 때문에 막아줘야 할 필요가 있음
- 이 연구에서는 scaled-dot product attention에서 모든 softmax의 input value 중 illegal connection에 해당하는 값을 −∞로 masking out해서 구현함
(3) Position-wise Feed-Forward Networks
- 인코더 디코더의 각 layer는 fully connected feed-forward network를 가짐
- 이는 각 position에 따로따로, 동일하게 적용됨
- ReLu 활성화 함수를 포함한 두 개의 선형 변환이 포함됨
- linear transformation은 다른 position에 대해 동일하지만 layer간 parameter는 다름
(4) Embeddings and Softmax
- 다른 sequence transduction models 처럼, 학습된 임베딩을 사용함
- input 토큰과 output 토큰을 dmodel 의 벡터로 변환하기 위함
(5) Positional Encoding
- Transformer는 어떤 recurrene, convolution도 사용하지 않기 때문에, sequence의 순서를 사용하기 위해 sequence의 상대적, 절대적 position에 대한 정보를 주입해줘야 함
- 인코더와 디코더 stack 아래의 input 임베딩에 "Positional Encoding"을 추가함
- Positional Encoding은 input 임베딩처럼, 같은 차원 (dmodel)을 가져서, 둘을 더할 수 있음
- 다양한 positional encoding 방법 중에, transformer는 다른 주기의 sine, cosine function을 사용함
- pos : position
- i : demension
- positional encoding의 각 차원은 sine 곡선에 해당함
- 모델이 상대적인 position으로 쉽게 배울 수 있을거라 가정하여 위 function을 사용함

- 두 방식은 거의 같은 결과를 보임
- transformer에선 sine 곡선의 방식을 택함